Где-то в 2015 все вокруг стали трансформироваться из техно-оптимистов в пессимистов. Капитализм повсеместно начинал закручивать гайки в цифровых продуктах и сервисах. Пэйволы и реклама стали появляться там где ещё 3 года назад их даже представить было трудно. Бесплатные вчера сервисы обрастали подписками. Дуров убрал Стену, а Хабр ввёл политику «вы можете публиковать у нас что угодно, пока это размещено в платном блоге компании». Будущее опять оказалось наёбкой недобросовестных коммерсантов.
«Ура!», подумал я, «круг замкнулся и мы снова входим в эпоху имейлов, торрентов и обязательного хоумпейджа с гостевухой».
Нет никакого смысла пилить интересный лонгрид для siliconrus, если после ребрендинга и переезда на новый домен они потеряют все ассеты для него. Нет смысла публиковаться на Medium, если завтра они решат сменить плохое оформление на хуёвое потому что так конверсия в подписку на 0.003% выше. Твое мнение ничего не значит. Ты просто цифра в логах чужого компьютера, который теперь называется «облако». А раз так, то пусть это будет мой компьютер. Настала пора делать хомяка!
К 2019 всё стало ещё хуже
Технологии 2015
Сайт должен был быть статичным. Меня не интересовали даже каменты на нём. По идее он должен был стать дедушкиным шкафом в котором были бы аккуратно расставлены заметки и, может быть, описаны какие-то личные проекты. Дверцы стеклянные — смотри сколько влезет, но ключ есть только у меня.
Вот как была сформулирована цель в документе с требованиями: «Сделать личный сайт, который будет нерегулярно (никаких сраных блогов) наполняться контентом на вёрстку которого я не буду жалеть времени. Фактически, нужна система публикации текстов отвязанная от всего проприетарного говна типа медиума, фейсбука и пр.»
Раз удобство вёрстки не важно, то Wordpress и другие популярные php-based движки с разухабистыми WYSIWYG админками, системой плагинов и возможностями публикации прямо с сайта не рассматривались.
Другим важным требованием была простота миграции. Прежде чем выбрать тулу подумай как ты в будущем будешь с неё слазить ведь рано или поздно она, как и всё остальное, превратится в банк.
Поковырявшись, я остановился на таком наборе:
- Jekyll в качестве генератора статики. Быстрый, отлично документирован. Посты на любимом Markdown. Статику легко деплоить простым копированием. Используется в GitHub Pages.
- VS Code как редактор. Перспективный редактор в котором я уже вёл заметки.
- Jenkins для CI/CD. Хотелось автоматизировать всё с самого начала.
- GitHub для хранения исходников.
- Hetzner для хостинга сайта. Никогда с ним раньше не работал и хотел попробовать. VPS на Linux + NGINX.
Шаблоны
Макс рисовал шаблоны, а Гриша сверстал их нахрапом за один подход. Основными требованиями к внешнему виду были чистота типографики и фокус на тексте. Текст вообще король. Мне просто нравится как выглядят буквы пусть они набраны даже обычным Open Sans.
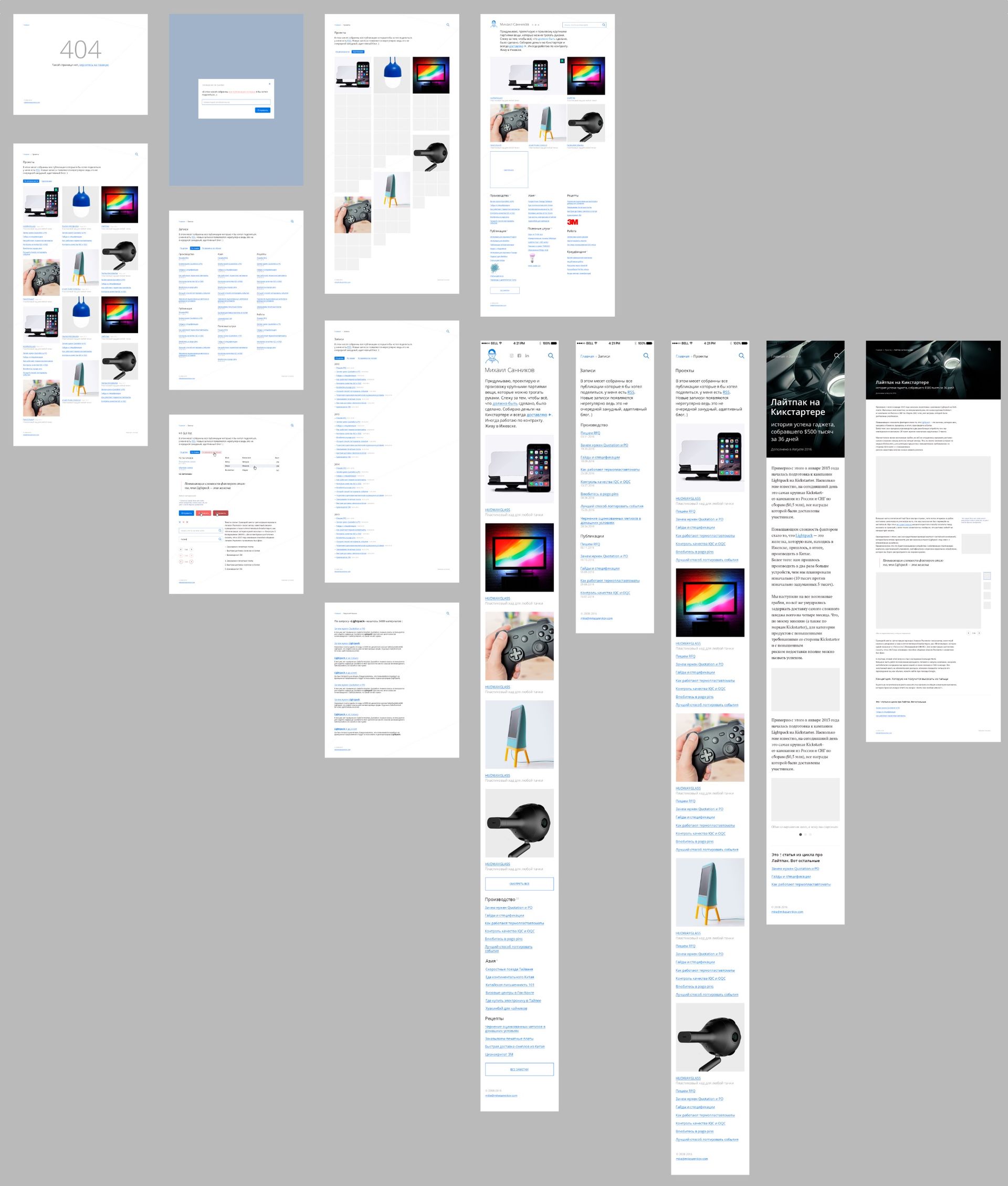
1 В сайдбар можно засунуть любой текст, картинку, и даже embed. Поддерживается Markdown.
Важным требованием был сайдбар справа от текста абзаца1. Я знаю что не умею писать без поясняющих скобок и мне давно хотелось научиться. Сайдбар должен был спасти текст от подробностей, которые многие сочли бы ненужными. Мы не показываем сайдбар в мобильной версии страницы.
Читатель увидит разное кол-во контента в зависимости от того с какого устройства откроет страницу.
Структура сайта очень простая
- Главная витрина. Она наполняется вручную.
- Страницы-агрегаторы «Список статей» и «Список проектов». Формируются автоматически, имеют «нескучные сортировки».
- Сервисные страницы-сироты. Например
/pages/404/. - Страницы с контентом. Они составляют основную массу сайта.
Front Matter и переменные Liquid
Jekyll обрабатывает и генерирует .html только из .md в которых есть шапка метаданных в виде YAML front matter. При помощи этого блока можно управлять атрибутами и переменными будущей страницы, применять к ней разные шаблоны, теги и другие признаки.
В 2018 мета для типичной страницы выглядела так:
---
layout: post
category: articles
date: 2015-03-28
updated: "обновлено в сентябре 2016"
title: Большая и важная заметка
description: Тестирование Джекила не может быть простым процессом, по возможности старайтесь избегать такого
tags: [Котики, Смерть]
assets: /assets/posts_data/2015-03-28-the-big-test-journey
background: /assets/posts_data/2015-03-28-the-big-test-journey/2015-03-28-title-back-1920x490.jpg
---
<!-- тут md и html -->
Поля во Front Matter говорят сами за себя. Обратите внимание что тэги и категории существуют отдельно. Html-шаблон страницы задаётся в атрибуте layout, а updated это вовсе строка, которая выводилась на странице как есть.
2 Потому что у каждого поста есть собственная папочка с картинками.
Отдельно нужно сказать про переменные типа assets или background. В них я указываю путь до папки с картинками для этого конкретного поста2. Это удобно потому что позже при вставке картинок вместо ссылки типа /assets/posts_data/2015-03-28-the-big-test-journey/pic.png можно вставить {{page.assets}}/pic.png и Джекил сделает всё остальное.
Можно добавлять собственные атрибуты и переменные и потом лихо переиспользовать их в сортировках, коллекциях, да и пофиг где.
Выразительные средства и HTML для странного
В 2018 в постах помимо основного форматирования маркдаун можно было использовать карусели картинок, одинокие картинки с подписями, контент в сайдбаре, списки, таблицы, подсветку синтаксиса и, пожалуй, всё.
Особняком стояла заглавная картинка поста: Макс нарисовал её на всю ширину экрана и это было красиво, но 4K мониторы с 2015 сильно проникли в наш быт и делать широченные картинки с соотношением 5:1 так чтобы они не обрывались по краям мониторов становилось всё сложнее.

Как, по-вашему, такая заглавная картинка будет выглядеть на 300 ppi? Пример из чужого блога.
Всё, что не умел маркдаун приходилось вставлять через html. В 2015 до этого не было никакого дела т.к. вёрстка не занимала много времени, а контент не писался сразу в прод и готовился сначала в каких-нибудь гуглдокументах. Из-за этого html кода было очень много. Код сильно мешал читать файл. Получалось, что писать и верстать — два совершенно разных процесса. Примерно с 2018 я начал потихоньку унифицировать этот опыт заменяя всё что можно liquid тегами с целью полностью избавиться от html в .md файлах.
Вот для чего мы использовали html в 2018:
- Карусели картинок
- Контент в сайдбаре и циферки-рефы на него
- Эмбеды включая Ютюб, карты, коубы и пр.
- Подножие с похожими постами и финальная круглая картинка
- Раскрывающиеся блоки
Например, так выглядела строка со сноской в сайдбаре. Ручной менеджмент циферок в сносках мог превратиться в сущий ад, если текст поста был достаточно длинным.
<p class="note"><sup>2</sup> Приблизительно такого. В нём даже можно <a href="http://www.snnkv.com">использовать ссылки</a>.</p>
Ещё, к сайту до 2019 года был подключен Font Awesome, что тогда казалось мне невероятно прогрессивным. Возможность вставить любую иконку из векторного набора при помощи короткой строки казалась супер фичей. Правда быстро выяснилось что это максимально бесполезный кусок джаваскрипта на который можно потратить пользовательскую память. Ведь даже из эмодзи мы используем всего 5-7 иконок. 🤦🏻♂️
Поиск
3 А он нарисовал страницу поисковой выдачи.
Не то, чтобы поиск был мне сильно нужен и он уже точно не был нужен в первую очередь, когда на сайте буквально нечего было искать. Но что Макс нарисовал3, то Гриша сверстал.
В качестве движка для поиска по статике был выбран lunr.js. Он завёлся с первого раза и неплохо искал, особенно после небольшого тюнинга. Однако, довольно быстро была выявлена проблема: ссылки на «похожие статьи» в подножии страниц тоже брались в расчёт и никаких простых способов пессимизировать их или вовсе убрать из индекса не было. Проблема нас из будущего.
Сборка и деплой
С самого первого дня существования сайта я зарылся в CI/CD для него. Мне было интересно поковыряться с процессом и одновременно разобраться с тем как это устроено в современном вебе. Вот список процессов которые первыми пришли на ум:
- Статику где-то нужно было собирать. На моем макбуке это занимало около 3 секунд. В основном это было связано с тем, что для сборки я использовал просто
jekyll build --clean, который никак не обрабатывал картинки, а просто копировал их в нужные места. 1.Исходники сайта нужно было где-то хранить. Для этого был выбран очевидный на тот момент вариант — GitHub. Причём я хранил всё в одном репозитории, включая ассеты и картинки. Пока постов было не много это не было проблемой. - После сборки папку с подготовленными
.htmlфайлами нужно было скопировать на веб-сервер и при помощи симлинков переключить старую версию на новую желательно сохранив прошлую версию на всякий случай. - После деплоя нужно проверить результат. Именно новая версия сайта должна отзываться на основном домене.
Это был необходимый минимум. Среди дополнительных опций на столе лежали:
- Зеркало. Копия сайта на отдельном домене на который можно заливать экспериментальные сборки или проводить стэйджинг.
- Валидация html кода который сгенерил Джекил. Проверка корректности ссылок и разных обязательных атрибутов тегов.
- Уведомления о всём этом бардаке по какому-то удобному каналу.
В качестве основных инструментов были выбраны Jenkins, HTMLProofer и пара скриптов написанных на bash. Первая версия процесса в 2017 выглядела так:
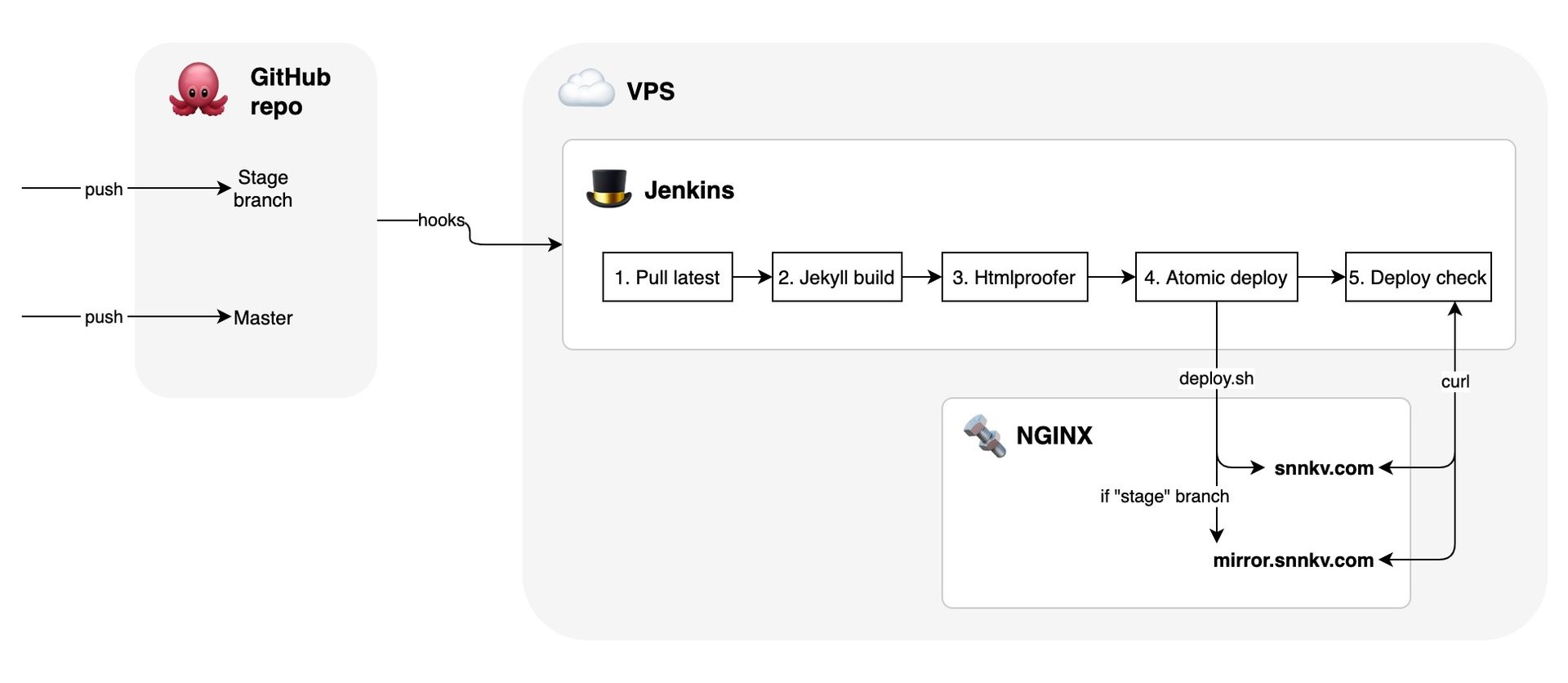
Без объяснений не обойтись:
- Основной рабочей веткой была stage. В master можно было только мерджить из stage. Таким образом ничто не уйдёт в прод мимо стэйджа.
- После пуша на Гитхаб, Дженкинс сразу же подтягивал последние изменения и начал собирать из них сайт при помощи Джекила.
- После этого по всем файлам статики проходился htmlproofer. Это довольно всратая тула, но с кругом задач из 2017 она справлялась отлично. Билды регулярно крешились на этом этапе из-за битых ссылок, отсутствующих
alt=в<img>и других детских болезней вызванных ручной вёрсткой. - Для публикации проверенных файлов существовал простенький скрипт на bash который делал всю нужную магию с подменой симлинков и сохранением прошлой версии сайта. В 2017 такое называлось Atomic Deploy и позволяло обновлять сайт мгновенно и незаметно для посетителей.
- Последним шагом я проверял версию сайта при помощи другого скрипта. Идея была простая: во время коммита выполнялся скрипт через механизм git pre-commit hook. Он записывал текущую SHA коммита в специальный файл внутри дирректории
/_data. Во время сборки, Джекил читал эту строку и помещал её в подножие сайта. Вы можете увидеть её прямо сейчас. После публикации сайта curl бажала на главную и выковыривала эту же строку из DOM, а потом сравнивала её с SHA коммита. Так я проверял что сайт опубликован и светится наружу.
4 А ещё Дженкинс физически находился на той же машине, что и сам сайт, что было временным, но всё же тупым решением.
Всё в этой схеме работало прекрасно и быстро кроме того, что Дженкинс то и дело умирал и переставал отвечать. Из 10 сборок 2 не отзывались. Поковырявшись мы выяснили, что ему просто не хватает оперативки4.
Поэтому в 2018 я перевёз всю эту CI инфру на молодой, нетрендовый и подающий надежды Buddy.Works с которым сайт прожил почти год. В итоге схема стала выглядеть примерно так:
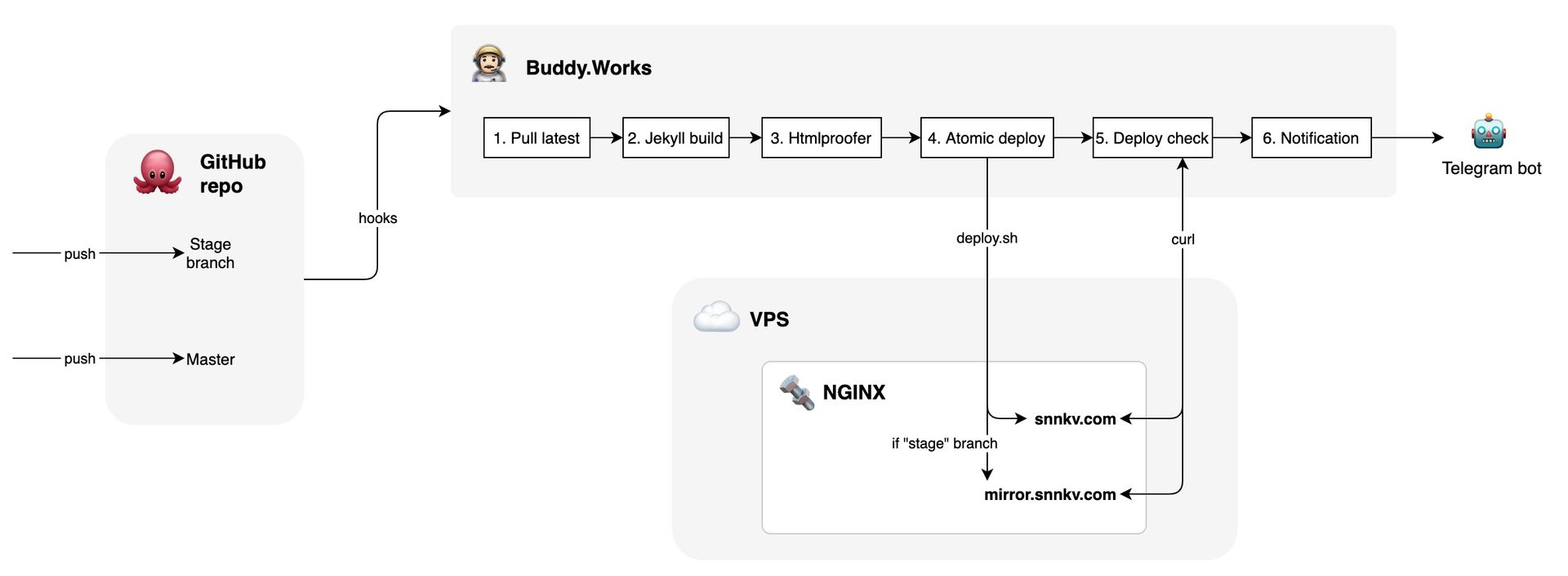
В целом, скорость сборки и деплоя снизилась из-за того что каждый этап выполнялся в изолированном контейнере, да ещё и на неизвестно где находящейся машине. Зато весь процесс работал как часы и его не нужно было обкладывать костылями.
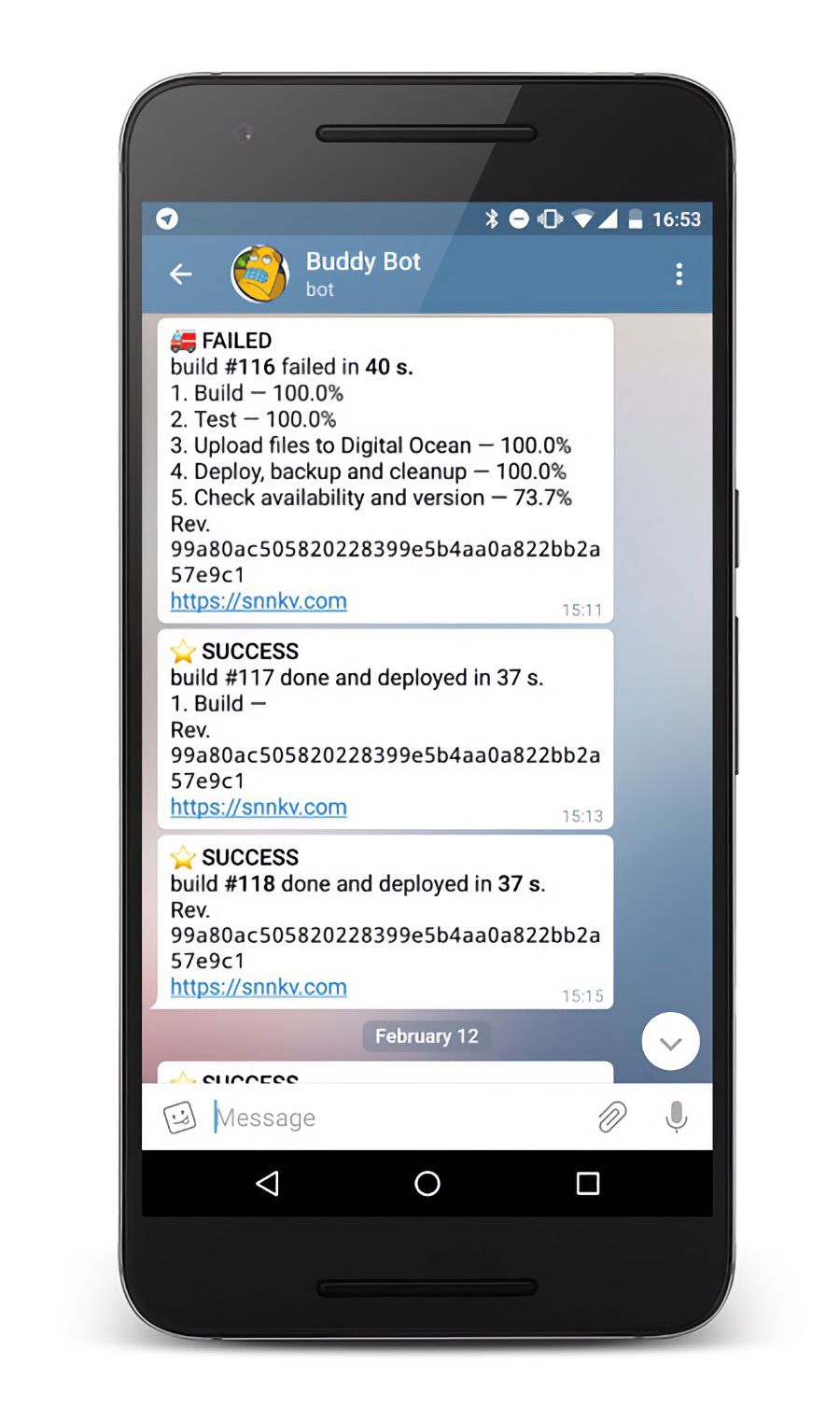
Обратите внимание, что в схеме появились уведомления через Телеграм, которые благодаря переменным Buddy были хорошо профилированы по этапам, время выполнения каждого из которых можно было отследить.
Документация
У меня потрясающая способность забывать всё, что связано с написанным кодом, через сутки. Через месяц я смотрю на собственный код как в первый раз. Из-за этого, когда стало ясно, что хомяк — долгоиграющий проект в котором будут паузы и ускорения, я начал документировать основные фичи, чтобы по несколько раз не проходить один и тот же путь.
Основное, что касается вёрстки и оформления статей собрано на отдельной странице, а всё что связано с подкапотными делами типа настройки CI/CD и NGINX вообще свалено в отдельный репозиторий. Это удобно потому что все эти шпаргалки обновляются синхронно с сайтом и версию всегда можно откатить вместе со всеми доками.
Удивительно, но хомяк быстро превратился в приятный процесс ради процесса и мы научились получать от ковыряния в нём удовольствие. Публикация и релиз уже не были чем-то важным. Дзен пет-проджект для двух с половиной человек.
⚠️ Каменты в режиме эксперимента. Нужна регистрация на GitHub и необходимо дать разрешение боту Giscus. Если это неприемлемо, можно комментировать прямо на GitHub.